

5·
2 days agoIf you’re behind Cloudflare, don’t. Just get an origin certificate from CF, it’s a cert that CF trust between itself and your server. By using Cloudflare you’re making Cloudflare responsible for your cert.
If you’re behind Cloudflare, don’t. Just get an origin certificate from CF, it’s a cert that CF trust between itself and your server. By using Cloudflare you’re making Cloudflare responsible for your cert.
There’s also Cockpit if you just want a basic UI

You can also nest rootful Xwayland in there too!
From the user’s shell,
WAYLAND_DISPLAY=/run/user/1000/wayland-0 Xwayland :1 &
export DISPLAY=:1 WAYLAND_DISPLAY=
i3 &
xterm &
konsole &
Of course you that means you can also run Plasma X11 that way for example:
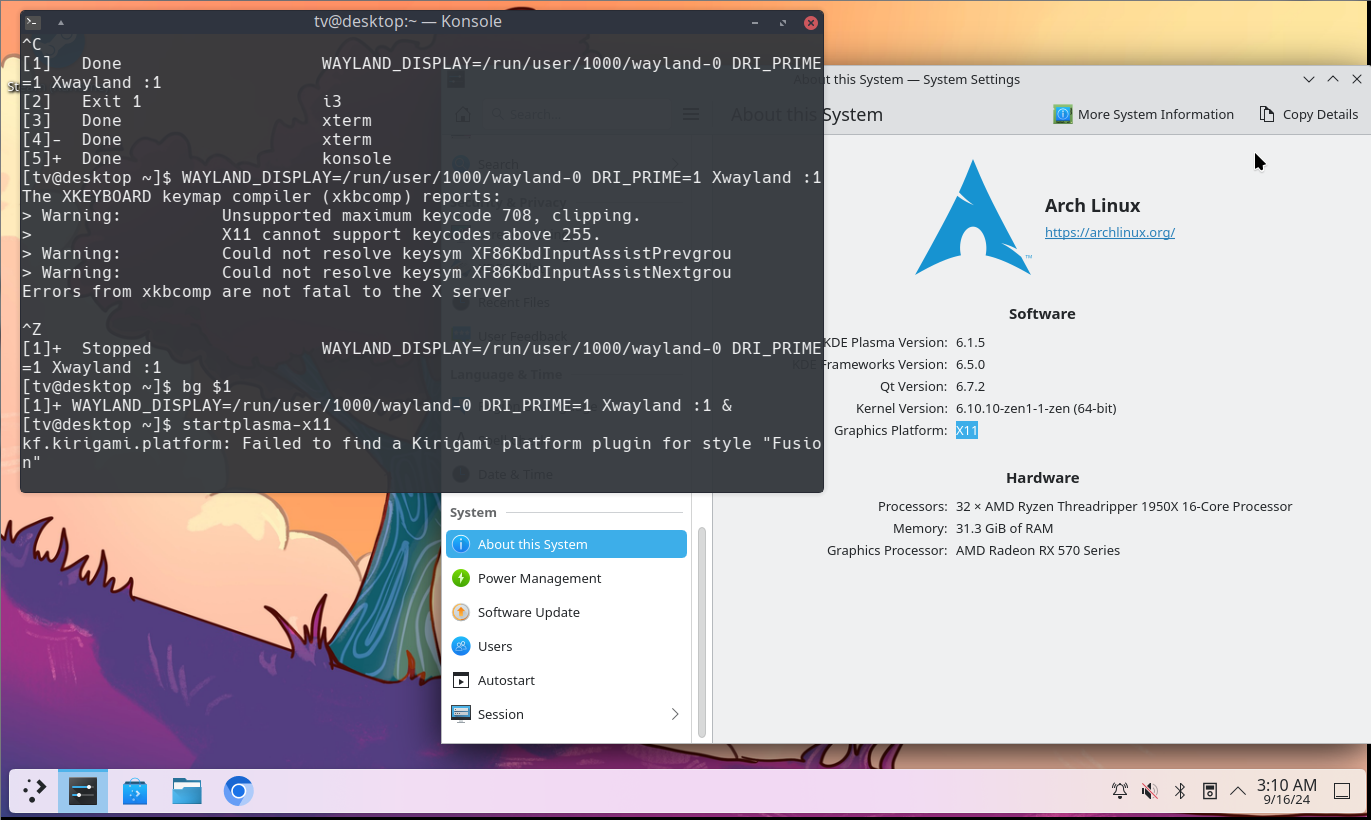
Make sure to use machinectl and not sudo or anything else. That’s about the symptoms I’d expect from an incomplete session setup. The use of machinectl there was very deliberate, as it goes through all the PAM, logind, systemd and D-Bus stuff as any normal login. It gets you a clean and properly registered session, and also gets rid of anything tied to your regular user:
max-p@desktop ~> loginctl list-sessions
SESSION UID USER SEAT LEADER CLASS TTY IDLE SINCE
2 1000 max-p seat0 3088 user tty2 no -
3 1000 max-p - 3112 manager - no -
8 1001 tv - 589069 user pts/4 no -
9 1001 tv - 589073 manager - no -
It basically gets you to a state of having properly logged into the system, as if you logged in from SDDM or in a virtual console. From there, if you actually had just logged in a tty as that user, you could run startplasma-wayland and end up in just as if you had logged in with SDDM, that’s what SDDM eventually launches after logging you in, as per the session file:
max-p@desktop ~> cat /usr/share/wayland-sessions/plasma.desktop
[Desktop Entry]
Exec=/usr/lib/plasma-dbus-run-session-if-needed /usr/bin/startplasma-wayland
TryExec=/usr/bin/startplasma-wayland
DesktopNames=KDE
Name=Plasma (Wayland)
# ... and translations in every languages
From there we need one last trick, it’s to get KWin to start nested. That’s what the additional WAYLAND_DISPLAY=/run/user/1000/wayland-0 before is supposed to do. Make sure that this one is ran within the machinectl shell, as that shell and only that shell is the session leader.
The possible gotcha I see with this, is if startplasma-wayland doesn’t replace that WAYLAND_DISPLAY environment variable with KWin’s, so all the applications from that session ends up using the main user. You can confirm this particular edge case by logging in with the secondary user on a tty, and running the same command including the WAYLAND_DISPLAY part of it. If it starts and all the windows pop up on your primary user’s session, that’s the problem. If it doesn’t, then you have incorrect session setup and stuff from your primary user bled in.
Like, that part is really important, by using machinectl the process tree for the secondary user starts from PID 1:
max-p@desktop ~> pstree
systemd─┬─auditd───{auditd}
├─bash─┬─(sd-pam) # <--- This is the process machinectl spawned
│ └─fish───zsh───fish───zsh # <-- Here I launched a bunch of shells to verify it's my machinectl shell
├─systemd─┬─(sd-pam) # <-- And that's my regular user
│ ├─Discord─┬─Discord───Discord───46*[{Discord}]
│ ├─DiscoverNotifie───9*[{DiscoverNotifie}]
│ ├─cool-retro-term─┬─fish───btop───{btop}
│ ├─dbus-broker-lau───dbus-broker
│ ├─dconf-service───3*[{dconf-service}]
│ ├─easyeffects───11*[{easyeffects}]
│ ├─firefox─┬─3*[Isolated Web Co───30*[{Isolated Web Co}]]
Super weird stuff happens otherwise that I can’t explain other than some systemd PAM voodoo happens. There’s a lot of things that happens when you log in, for example giving your user access to keyboard, mouse and GPU, and the type of session depends on the point of entry. Obviously if you log in over SSH you don’t get the keyboard assigned to you. When you switch TTY, systemd-logind also moves access to peripherals such that user A can’t keylog user B while A’s session is in the background. Make sure the machinectl session is also the only session opened for the secondary user, as it being assigned to a TTY session could also potentially interfere.
what distro/plasma version are you running? (here it’s opensuse slowroll w/ plasma 6.1.4)
Arch, Plasma 6.1.5.
what happens if you just run startplasma-wayland from a terminal as your user? (I see the plasma splash screen and then I’m back to my old session)
You mean a tty or a terminal emulator like Konsole?
It’s a lot easier with Wayland and hardware acceleration works, see my solution. It does a proper login session and starts the whole DE exactly the same way as if you logged in from a tty too so everything just works as expected there. Wayland devs use that a lot for testing and development so it’s quite well supported overall.
Totally possible. It’ll work best with Wayland thanks to nested compositor support, whereas on Xorg you’d need to use Xephyr which doesn’t do hardware acceleration.
# Give the other user access to your Wayland socket
setfacl -m u:otheruser:rx $XDG_RUNTIME_DIR
setfacl -m u:otheruser:rwx $XDG_RUNTIME_DIR/wayland-0
# Open a session as the other user (note the trailing @, it's there to login in to the local machine)
sudo machinectl login otheruser@
# Start your DE!
WAYLAND_DISPLAY=/run/user/$(id -u yourmainuser)/wayland-0 startplasma-wayland
And tada! 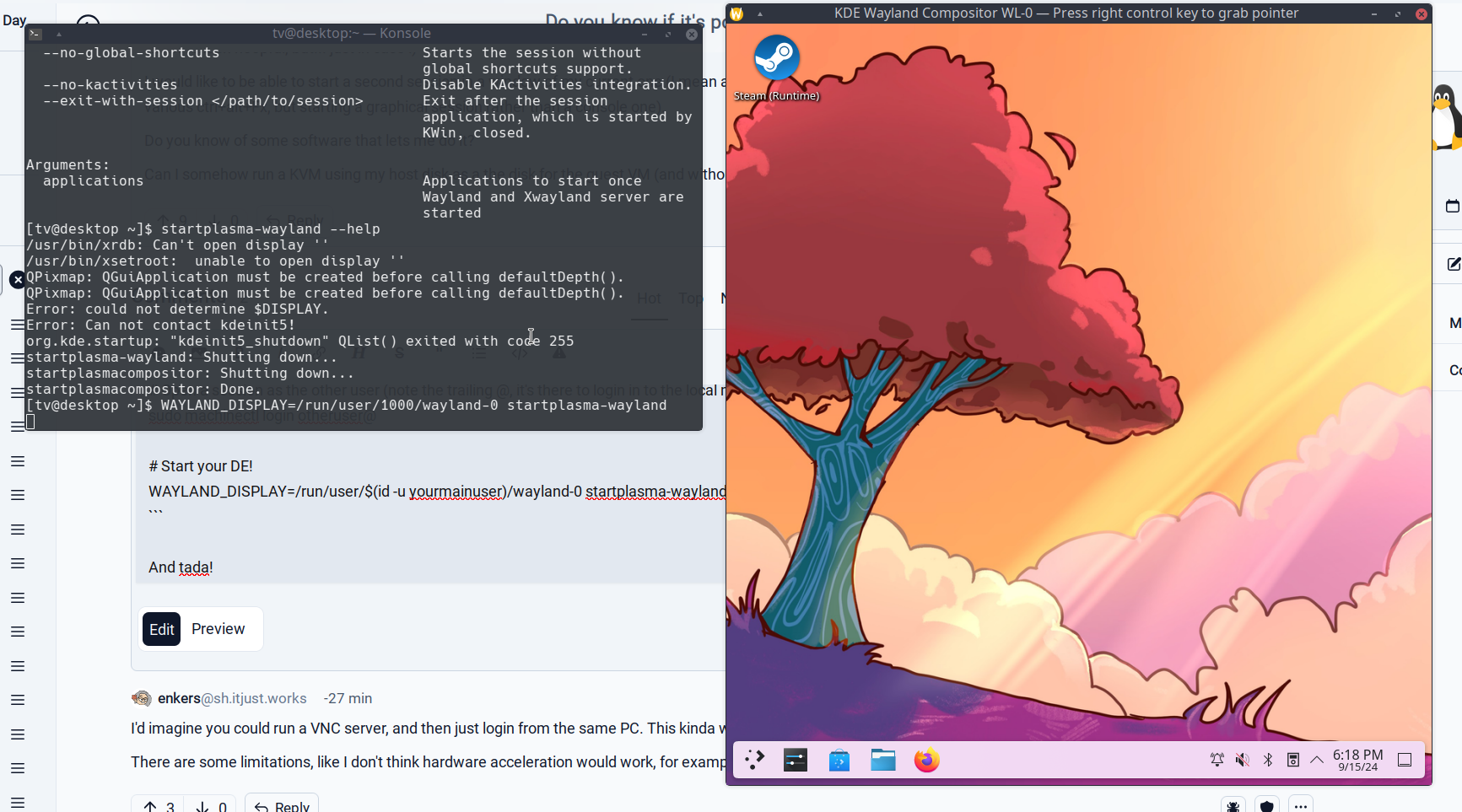

If you can find where the antenna is, you can cover it with some metal tape to kill the signal. Or wrap the whole thing on a metal cage or foil, basically put the thing in a faraday cage.
I have a feeling they’d put the antenna in the front panel though, so that solution may not be super aesthethic if that’s the case.
If you’re careful and just disconnect the antenna properly such that you can plug it back in it should be okay.

Does the morning coffee count? I’ll skip it if I’m being late but I do like my morning coffee.
I would use maybe a Raspberry Pi or old laptop with two drives (preferably different brands/age, HDD or SSD doesn’t really matter) in it using a checksumming filesystem like btrfs or ZFS so that you can do regular scrubs to verify data integrity.
Then, from that device, pull the data from your main system as needed (that way, the main system has no way of breaking into the backup device so won’t be affected by ransomware), and once it’s done, shut it off or even unplug it completely and store it securely, preferably in a metal box to avoid any magnetic fields from interfering with the drives. Plug it in and boot it up every now and then to perform a scrub to validate that the data is all still intact and repair the data as necessary and resilver a drive if one of them fails.
The unfortunate reality is most storage mediums will eventually fade out, so the best way to deal with that is an active system that can check data integrity and correct the files, and rewrite all the data once in a while to make sure the data is fresh and strong.
If you’re really serious about that data, I would opt for both an HDD and an SSD, and have two of those systems at different locations. That way, if something shakes up the HDD and damages the platter, the SSD is probably fine, and if it’s forgotten for a while maybe the SSD’s memory cells will have faded but not the HDD. The strength is in the diversity of the mediums. Maybe burn a Blu-Ray as well just in case, it’ll fade too but hopefully differently than an SSD or an HDD. The more copies, even partial copies, the more likely you can recover the entirety of the data, and you have the checksums to validate which blocks from which medium is correct. (Fun fact, people have been archiving LaserDiscs and repairing them by ripping the same movie from multiple identical discs, as they’re unlikely to fade at exactly the same spots at the same time, so you can merge them all together and cross-reference them and usually get a near perfect rip of it).

I don’t understand what’s up with the US and this will to always hand out the harshest punishment in every situation. Locking someone up for 20 years in prison does nothing to reform them, the whole system is designed for them to fail and get locked up again too. Can’t get jobs because you’re forever tagged as a felon, and the conditions are so harsh nobody can employ them anyway because they can barely do a normal 9-5 because they put probation appointments in the middle of the day so you always have to ask for time off, can’t do overtime because you have to be home outside of 9-5. All those institutions are biased towards locking them up again because that’s how they make money, it’s in their financial interest and duty to shareholders to keep a market of criminals to lock up.
The only option left for those people upon release is to go right back to crime because that’s the only thing that doesn’t discriminate against them forever and allows them to make sufficient money, or jobs that are basically slavery with extra steps.
And in this case it’s pretty clear they got the biggest possible sentence because they weren’t white.
Upon Ms. Polk’s release, she earned a doctorate in public policy and administration and is an advocate for the elderly
That seems like a perfect example of someone that has been reformed and is no longer deserving of punishment. Only someone made out of pure anger would have a problem with that.
The real victim here is the poor souls that have to use Oracle products
I believe you, but I also very much believe that there are security vendors out there demonizing LE and free stuff in general. The more expensive equals better more serious thinking is unfortunately still quite present, especially in big corps. Big corps also seem to like the concept of having to prove yourself with a high price of entry, they just can’t believe a tiny company could possibly have a better product.
That doesn’t make it any less ridiculous, but I believe it. I’ve definitely heard my share of “we must use $sketchyVendor because $dubiousReason”. I’ve had to install ClamAV on readonly diskless VMs at work because otherwise customers refuse to sign because “we have no security systems”. Everything has to be TLS encrypted, even if it goes to localhost. Box checkers vs common sense.
LetsEncrypt certs are DV certs. That a put a TXT record for LetsEncrypt vs a TXT record for a paid DigiCert makes no difference whatsoever.
I just checked and Shopify uses a LetsEncrypt cert, so that’s a big one that uses the plebian certs.
Neither does Google Trust Services or DigiCert. They’re all HTTP validation on Cloudflare and we have Fortune 100 companies served with LetsEncrypt certs.
I haven’t seen an EV cert in years, browsers stopped caring ages ago. It’s all been domain validated.
LetsEncrypt publicly logs which IP requested a certificate, that’s a lot more than what regular CAs do.
I guess one more to the pile of why everyone hates Zscaler.
That’s more of a general DevOps/server admin steep learning curve than Vaultwarden’s there, to be fair.
It looks a bit complicated at first as Docker isn’t a trivial abstraction, but it’s well worth it once it’s all set up and going. Each container is always the same, and always independent. Vaultwarden per-se isn’t too bad to run without a container, but the same Docker setup can be used for say, Jitsi which is an absolute mess of components to install and make work, some Java stuff, and all. But with Docker? Just docker compose up -d, wait a minute or two and it’s good to go, just need to point your reverse proxy to it.
Why do you need a reverse proxy? Because it’s a centralized location where everything comes in, and instead of having 10 different apps with their own certificates and ports, you have one proxy, one port, and a handful of certificates all managed together so you don’t have to figure out how to make all those apps play together nicely. Caddy is fine, you don’t need NGINX if you use Caddy. There’s also Traefik which lands in between Caddy and NGINX in ease of use. There’s also HAproxy. They all do the same fundamental thing: traffic comes in as HTTPS, it gets the Host header from the request and sends it to the right container as plain HTTP. Well it doesn’t have to work that way specifically but that’s the most common use case in self hosted.
As for your backups, if you used a Docker compose file, the volume data should be in the same directory. But it’s probably using some sort of database so you might want to look into how to do periodic data exports instead, as databases don’t like to be backed up live since the file is always being updated so you can’t really get a proper snapshot of it in one go.
But yeah, try to think of it as an infrastructure investment that makes deploying more apps in the future a breeze. Want to add a NextCloud? Add another docker compose file and start it, Caddy picks it up automagically and boom, it’s live and good to go!
Moving services to a new server is also pretty easy as well. Copy over your configs and composes, and volumes if applicable. Start them all, and they should all get back exactly in the same state as they were on the other box. No services to install and configure, no repos to add, no distro to maintain. All built into the container by someone else so you don’t have to worry about any of it. Each update of the app will bring with it the whole matching updated OS with the right packages in the right versions.
As a DevOps engineer we love the whole thing because I can have a Kubernetes cluster running on a whole rack and be like “here’s the apps I want you to run” and it just figures itself out, automatically balances the load, if a server goes down the containers respawn on another one and keeps going as if nothing happened. We don’t have to manually log into any of those servers to install services to run an app. More upfront work for minimal work afterwards.
Yeah, that didn’t stop it from pwning a good chunk of the Internet: https://en.wikipedia.org/wiki/Log4Shell
IMO the biggest attack vector there would be a Minecraft exploit like log4j, so the most important part to me would make sure the game server is properly sandboxed just in case. Start from a point of view of, the attacker breached Minecraft and has shell access to that user. What can they do from there? Ideally, nothing useful other than maybe running a crypto miner. Don’t reuse passwords obviously.
With systemd, I’d use the various Protect* directives like ProtectHome, ProtectSystem=full, or failing that, a container (Docker, Podman, LXC, manually, there’s options). Just a bare Alpine container with Java would be pretty ideal, as you can’t exploit sudo or some other SUID binaries if they don’t exist in the first place.
That said the WireGuard solution is ideal because it limits potential attackers to people you handed a key, so at least you’d know who breached you.
I’ve fogotten Minecraft servers online and really nothing happened whatsoever.
Sorry for the YT Short, but of course the simpsons predicted this: https://youtube.com/shorts/rYb8geoO484
What kind of splitter? Not a hub or switch, just a passive splitter?
Those do exist to do 4x 100M links on a single pair each, but you can’t just plug those into a router or switch and get 4 ports, it still needs to eventually terminate as 4 ports on both ends.